Understanding the BERT language model
Posted By : Aakash Chaddha | 28-Apr-2020
Bidirectional Encoder Representations from Transformers
Understanding the BERT
Bidirectional Encoder Representations from Transformers is a deep learning language model published by Google AI researchers. It produces state of the art results for a variety of natural language processing tasks (11 NLP Tasks).
The main distinction of BERT among the other language models is that it understands a sequence bidirectionally, which gives BERT a deeper understanding of the sequence and its past sequence.
Terminology:
Transformers: Transformer is an algorithm, requiring two components (Encoder and Decoder) to turn one sequence into another.
Attention Mechanism: Attention Mechanism enables the decoder at each stage of the output generation to attend to different parts of the source statement.
Encoder: An encoder is an input network and generates a function of a map / vector / tensor. These characteristics of the vector carry the details, the properties that reflect the data.
Decoder: The decoder is a network that takes the function vector from the encoder (usually the same network configuration as the encoder but in opposite orientation) and gives the best fit to the real input or expected output.
WordPiece: A technique for segmenting words into NLP subword-level tasks where the vocabulary is initialized with all the individual characters in the expression, and then iteratively applied to the vocabulary the most frequent / likely variants of the symbols in the vocabulary.
Looking Behind:
Researchers have repeatedly demonstrated the importance of transfer learning in the field of computer vision— pre-training a neural network model on a defined problem, for example, ImageNet, and then doing fine-tuning — using the learned neural network as the basis for a new purpose-specific model. Researchers have shown in recent years that a common approach can be effective in many activities related to natural language.
A different approach is feature-based teaching, which is also common in NLP tasks and exemplified in the recent ELMo article. A pre-trained neural network in this method generates word embeddings which are then used as features in NLP models.
Under the BERT hood:
The Transformer encoder reads the entire sequence of words at once as opposed to directional versions, which interpret the text input sequentially (left-to-right or right-to-left). It is thus called bidirectional, although it would be more accurate to say it is non-directional. This feature allows the algorithm to know the meaning of a term dependent on all its contexts (the word's left and right).
BERT uses Transformer, a method of focus that learns contextual interactions in a text between words (or sub-words). The transformer comprises two different processes in its vanilla type— an encoder interpreting the text input and a decoder making a forecast for the mission. Since the aim of BERT is to create a language model, it only requires the encoder mechanism. Google explains the basic workings of the Transformer in a report.
Unique training strategies that help BERT to gain deep contextual understanding:
- Masked Language Model
- Next Sentence Prediction
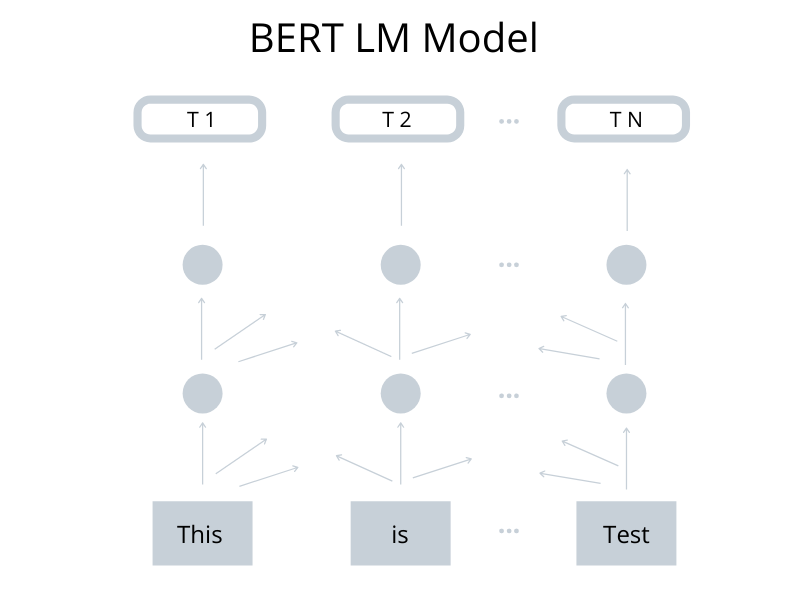
A simple illustration of the BERT Language Model.
Reference:


Cookies are important to the proper functioning of a site. To improve your experience, we use cookies to remember log-in details and provide secure log-in, collect statistics to optimize site functionality, and deliver content tailored to your interests. Click Agree and Proceed to accept cookies and go directly to the site or click on View Cookie Settings to see detailed descriptions of the types of cookies and choose whether to accept certain cookies while on the site.







About Author
Aakash Chaddha
He is a very ambitious, motivated, career oriented person, willing to accept challenges, energetic and result oriented, with excellent leadership abilities, and an active and hardworking person who is patient and diligent.